
 Aさん
Aさん 氏名や住所をLEFTやMIDなどで分割したいですが、データによって分割する位置が変わってしまいます。。
同じ数式で対応するには、どうしたら良いですか?
 森田
森田 その場合は、関数の「FIND」を活用し、区切り記号の位置をカウントすると良いですよ!
では、FINDの使い方について解説していきますね。
解説動画:【数式/関数#13】データ抽出/分割に役立つワークシート関数9選
この記事の内容は下記の動画でも解説しています。
コメント欄の各プロセスの時間部分をクリックすると該当の解説へジャンプできますよ!
はじめに
この記事は関数の概要とLEFT・RIGHT・MIDの使い方を把握していることが前提です。
関数の概要とLEFT・RIGHT・MIDの使い方の詳細は以下の記事をご参照ください。
解説動画 この記事の内容は下記の動画「【数式/関数#2】500種類以上の固有の計算/処理を自動化できる「関数」の前提知識/使い方まとめ」でも解説しています。 コメント欄の各プロセスの時間部分をクリックすると該当の解説へジ …

はじめに この記事は関数の概要を把握していることが前提です。 参考記事 関数の概要については以下の記事をご参照 …

はじめに この記事は関数の概要を把握していることが前提です。 参考記事 関数の概要については以下の記事をご参照 …

はじめに この記事は関数の概要を把握していることが前提です。 …

元データの区切り記号(文字)の位置をカウントしたい場合は「FIND」が有効
氏名や住所などのデータを2列以上に分割したい、あるいは一部を抽出したい場合、データによってはLEFTやMIDの引数「文字数」を同じ値で対応できないことがあります。
氏名であれば、データにより「氏」と「名」の文字数にバラツキがあるなどのケースです。
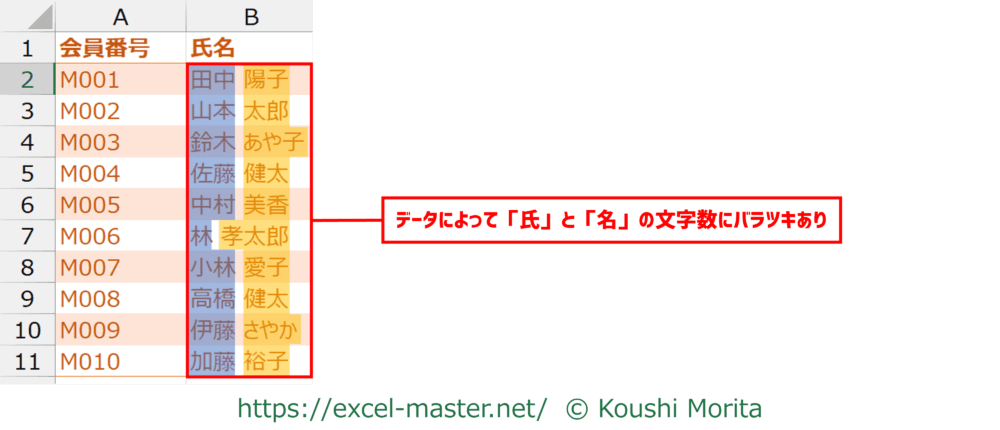
この解決策として、各データの「抽出/分割の目印となる文字」が何文字目にあるかをカウントすると良いです。
こうした文字のことを「区切り記号」または「区切り文字」と言います。
上記の例(氏名)であれば半角スペースが該当します。
この区切り記号の位置が分かれば、それを基準にデータ抽出/分割することで、同じ数式で文字数のバラツキに対応することが可能です。
この区切り記号の位置を検索するには、関数の「FIND」を使うと良いです。
ちなみに、FINDは「ファインド」と呼びます。
FINDを使えば、対象データ内で区切り記号が先頭から何文字目にあるか自動的にカウントすることが可能となります。
FINDの構文
FINDの構文は以下の通りです。
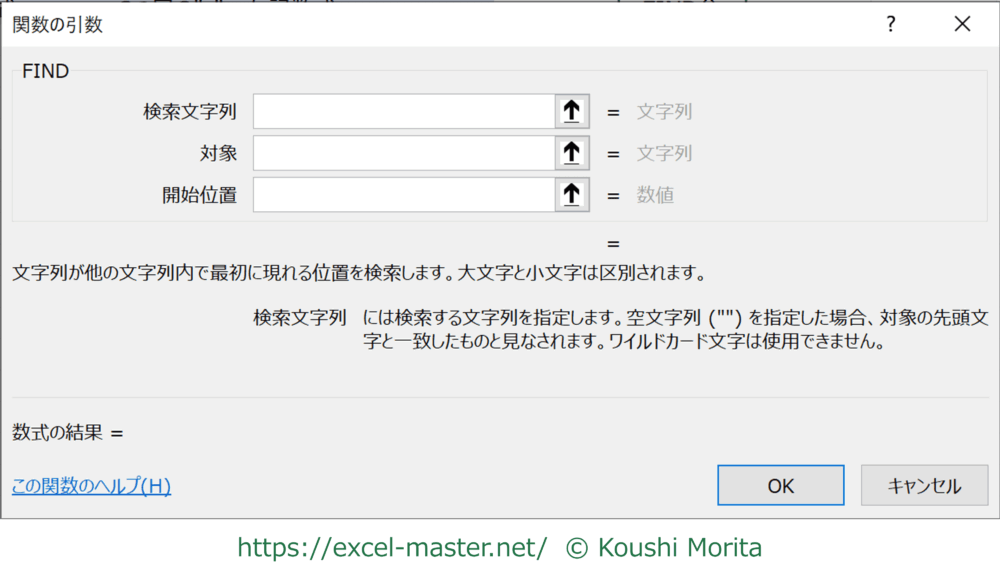
=FIND(検索文字列,対象,開始位置)
文字列が他の文字列内で最初に現れる位置を検索します。大文字と小文字は区別されます。
| 引数名 | 必須 | データ型 | 説明 |
|---|---|---|---|
| 検索文字列 | ○ | 文字列 | 検索したい文字列を指定します。 |
| 対象 | ○ | 文字列 | 検索対象のセルを指定します。 |
| 開始位置 | - | 数値 | 「対象」の何文字目から検索するか指定します。 ※「対象」の先頭文字は「1」 |
FINDは英字の大文字/小文字は区別されます。
引数「検索文字列」にブランク(””)を指定した場合、FINDの戻り値は「1」または引数「開始位置」の値になります。
引数「検索文字列」にワイルドカード(「*」や「?」)は使用できません。
引数「検索文字列」が引数「対象」から見つからなかった場合、エラー値「#VALUE!」が表示されます。
引数「開始位置」を省略すると、「1」を指定したと見なされます。
引数「開始位置」は「1」以上の数値を指定する必要があります(「1」未満の場合はエラー値「#VALUE!」が表示)。
引数「開始位置」へ引数「対象」の文字数を超える数値を指定した場合、エラー値「#VALUE!」が表示されます。
【参考】FINDは「文字列操作関数」
あくまで参考情報となりますが、FINDはリボン「数式」タブの関数ライブラリの「文字列操作」に分類されています。

実際にFINDを活用する際は、以下で解説しているように直接入力で挿入していきましょう。
FINDの使用結果イメージ
FINDを使い、対象データ内で区切り記号が先頭から何文字目にあるかカウントしたイメージは以下の通りです。
今回は「氏名」列のデータを対象に、半角スペースの位置をカウントしました。
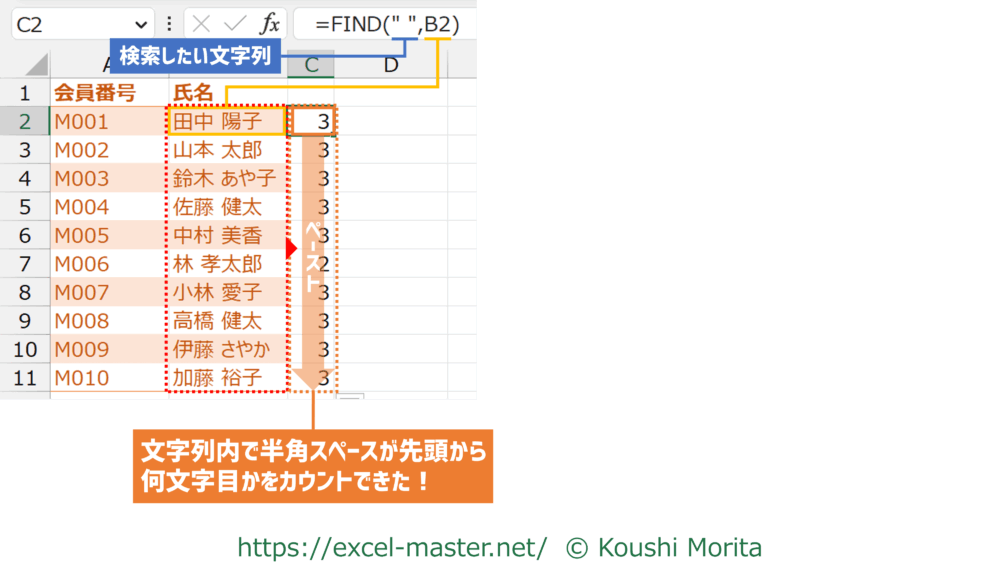
なお、FINDは原則一つの関数で一つのセルのみが検索対象です。
ベースの数式をセットしたら、他のセルへペーストしましょう。
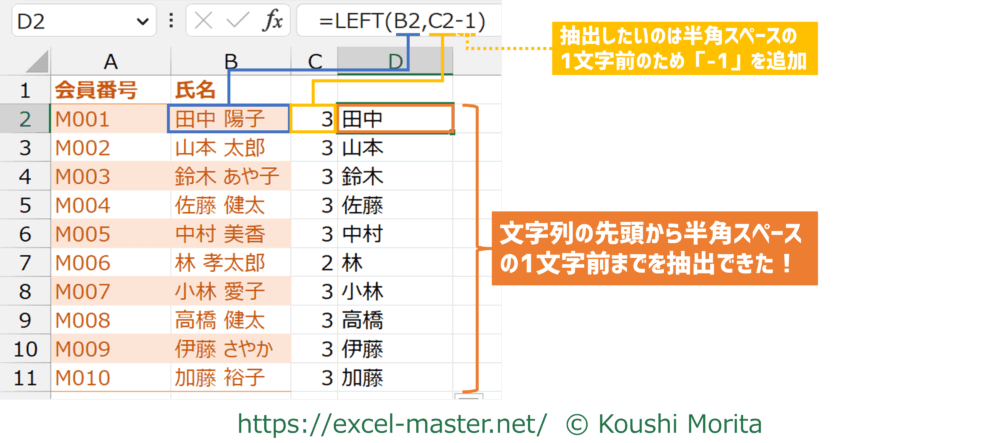
あとはLEFTなどの引数「文字数」にFINDの戻り値を参照し、必要に応じて四則演算で調整すればOKです。
LEFTなどの関数内に直接FINDをネストしてもOKです。
【参考】引数「開始位置」の活用イメージ
通常、引数「開始位置」は省略した状態で問題ないです。
引数「開始位置」の使いどころとしては、対象データ内で2回目以降に登場する区切り記号をカウントしたい場合に指定すると良いでしょう。
一例として、電話番号に2つあるハイフン(–)の位置をそれぞれカウントしたものが以下です。

引数「開始位置」に指定する値は、区切り記号の位置がデータによってバラツキの有無を踏まえて可変にするかどうか決めると良いでしょう。
バラツキがないなら固定値、バラツキがあるなら上記の例の通り、2つ目以降のFINDは1つ前のFINDの戻り値を活用すると良いです。
FINDの数式の挿入手順
上記の結果を得るための手順は以下の通りです。
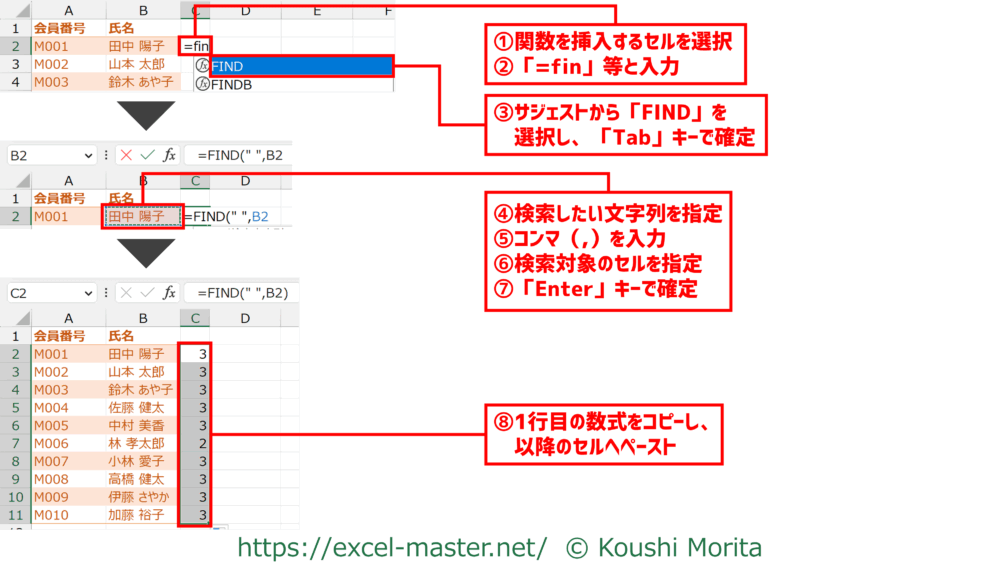
- 関数を挿入するセルを選択
※今回はC2セル - 「=fin」と入力
- サジェストから「FIND」を選択し、「Tab」キーで確定
- 検索したい文字列を指定
※今回は” ”(半角スペース) - コンマ(,)を入力
- 検索対象のセルを選択
※今回はB2セル - 「Enter」キーで確定
- 1行目の数式をコピーし、以降のセルへペースト
※今回はC3~C11セルへペースト
手順②の際にIMEを半角英数モードにすること。
テーブルの場合、手順⑧は不要(全レコードへ数式が自動的にコピーされる)。
【参考】半角と全角を区別して検索したい場合は「FINDB」
FINDで行う検索は、半角(1バイト)と全角(2バイト)を区別せず、1文字を「1」としてカウントします。
もし、半角と全角を区別して検索したい場合は「FINDB」(ファインドビー)を使いましょう。
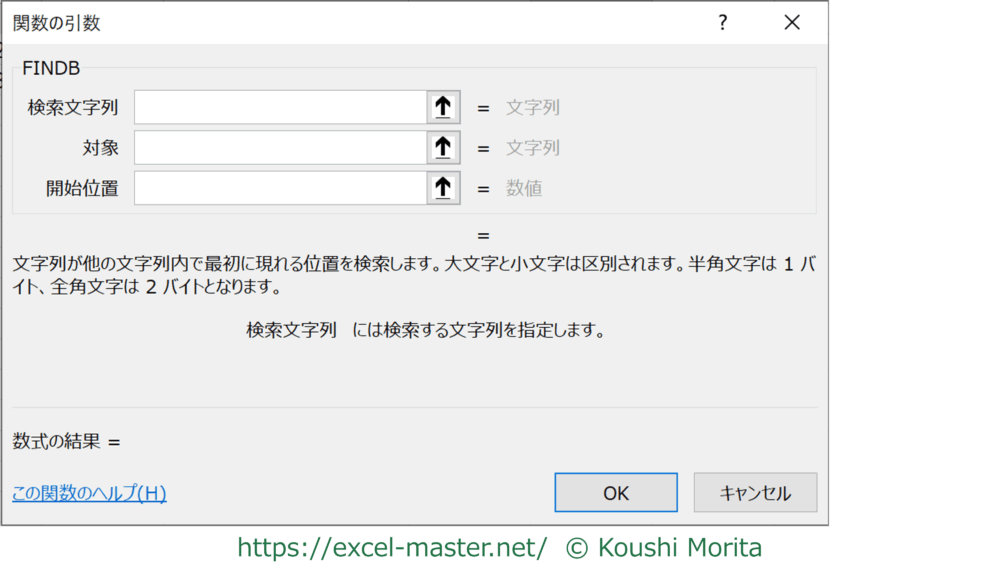
=FINDB(検索文字列,対象,開始位置)
文字列が他の文字列内で最初に現れる位置を検索します。大文字と小文字は区別されます。半角文字は1バイト、全角文字は2バイトとなります。
この関数の「1」は1バイトを示し、バイト数を基準に区切り記号の位置をカウントすることが可能です。
1文字が1バイトに変わるだけで、使い方自体はFINDと同様です。
【参考】英字の大文字と小文字を区別せずに検索したい場合は「SEARCH」
FINDで行う検索は、英字の大文字と小文字を区別し、別の文字としてカウントします。
もし、英字の大文字と小文字を同じ区別せず、同じ文字としてカウントしたい場合は「SEARCH」を使いましょう。
FINDとSEARCHの違いは以下の記事をご参照ください。
前回・前々回と任意の文字列が対象データの何文字目にあるかカウントするための方法としてFIND関数とSEARCH …

サンプルファイルで練習しよう!
可能であれば、以下のサンプルファイルをダウンロードして、実際に操作練習をしてみてください。
※サンプルファイルのダウンロードには無料メルマガに登録いただく必要があります。
(上記リンクから登録フォームへ遷移します)
ブックを開いたら、次の手順を実施してください。(今までの解説のまとめです)
- 関数を挿入するセルを選択
※今回はC2セル - 「=fin」と入力
- サジェストから「FIND」を選択し、「Tab」キーで確定
- 検索したい文字列を指定
※今回は” ”(半角スペース) - コンマ(,)を入力
- 検索対象のセルを選択
※今回はB2セル - 「Enter」キーで確定
- 1行目の数式をコピーし、以降のセルへペースト
※今回はC3~C11セルへペースト
本記事の解説と同じ結果になればOKです!
さいごに
いかがでしたでしょうか?
FINDは区切り記号を基準としたデータ抽出/分割に役立つ関数の一つです。
定期的にデータ抽出/分割の作業を行う機会があるなら、ぜひ覚えておいた方が良いですね。
なお、FIND以外にもExcelでのデータ整形の各種テクニックを拙著で解説していますので、こちらも参考にしてみてください。



また、よりコアな情報を発信していくために「公式LINE」を開始しましたので、ご興味があれば以下バナーから友だち追加をお願いします!
特典として、Excelワークシート関数一覧(計22スライド)やExcelショートカットキー一覧(計25スライド)等をプレゼント!

ご参考になれば幸いですm(_ _)m
森田 FINDを単独で使うケースは稀です。
基本はLEFTやRIGHT、MIDと組み合わせて使うことがほとんどですね。
なお、臨機応変に抽出/分割するためには、LENも覚えておくとベターですね。